Let's define the parameters for assessment for computer vision models:
Accuracy
The number of times a model correctly comes to the conclusion that it should detect an object in front of a camera.
Precision
The frequency at which the model can successfully generalize from the information it already has and gets it right.
Confidence
How often the model will generate false positives or false negatives. Another way to say this is how highly trained is the model to be able to determine that the identification is correct?

Confidence Scores in Computer Vision and Object Identification
Billions of dollars have been invested in creating computer vision models intended to solve problems in daily life and ultimately drive adoption. So why aren't these platforms more integrated into our lives? Consider the manless marketplace of the future. For our purposes, we will refer to it as Cramazon Go. The premise was, customers enter the store by scanning a QR code from the Cramazon app, this links them to their account on premise to start their shopping session. Ceiling cameras were supposed to do everything from track consumer behavior to validate purchases to understand inventory counts. In theory, computer vision is the tool to do all of this successfully. The result, an offsite non-automated team tracking consumer purchases, manually deploying payment to maintain the facade of a labor-less marketplace. All of this comes down to the binary nature of data coupled with the model's ability to choose to infer an object, assess the gray area of a request, and then get the identification right. So why didn't Cramazon Go work?
Object identification operates in assessing the in-between. A model has been trained to recognize a black pen, but when presented with a gray pen, will it first choose to detect the pen, second understand that the pen is not a black pen, and third reject it or fourth decide because it's not a black pen it's instead something else, a magic marker? Confidence metrics are a result of how fine tuned the model is to make a choice in a certain direction. Levels of confidence assigned to object identification are often manually made based on what we ultimately want the model to do. High confidence means that the model will do its best to only detect exactly what it's been trained on, no exceptions, no room for alternatives. Low confidence means that during identification, the model is more open to variables in the detection. Confidence scores do not equal performance; they are more a general barometer for assessing why a model is making a decision.
EXAMPLE
The model has been trained to identify a white horse. The object detection model is presented with a pre-packaged white unicorn.The model has high confidence; assigned to white horses. It reports back that this object is a banana.
Precision and Data a Working Relationship
Artificial Intelligence models are like recipes built from different ingredients. And, each model has a purpose.The effectiveness and precision of the model, and ultimately, the confidence scores start with the engine. Engines are frameworks for the logic a model deploys to put the pieces together; it is the thinking, the chef in the kitchen, of our analogy.
Every engine has positives and negatives, and parts of engine frameworks can be used with original code, libraries from other platforms to supplement core capabilities or create new ones. When consumers are evaluating which computer vision platform to use, it's important to understand the engine. Is it a pre-existing engine that has been wrapped with a SaaS for a specific purpose? And, what were the algorithms designed to do? Algorithms are designed for data types or desired outcomes. Examples include game learning, robotics, or certain types of decision making trees.
How a model performs, and ultimately its utility and scalability for the end user, is determined in large part by the ingredients that go into the engine. Precision, or the likelihood that the model will take the next and right step, is predicated on the engine and the data that it's trained on.
In the market right now, computer vision model creation is a several step process.
1
A single foundational object is documented through roughly
1,000 images.
2
The images are assembled into a 3D rendering in a virtual environment.Generally, this means that the raw images are being supplemented by either CGI or CG to fill in any part of the image that wasn't captured or that the algorithm failed to recognize in order to create the render or simulation.
3
The images that make up the 3D rendering are manually annotated and labeled by huge offsite teams.
4
The object is ready to be identified, and the model is created taking several weeks.
The highest theoretical precision score is 100% or 1.0. The best computer vision models on the market as of 2025, averaged a .7 precision score.
Precision is about generalization, the engine's ability to be able to fill in the blanks between what it is presented with and the final detection result. Going back to our unicorn example, there are several reasons the model mis-identified the object. Precision is a result of what kind of data the model is trained on and how it uses it. For example, if the white horse object was created using 1,000 raw images of white horses and assigned 90% confidence that leaves almost no room for interpretation. The model is unable to identify the prepackaged unicorn after mining through all the raw data; it turns to the next best thing, high confidence assigned to a white horse. This is not a white horse, so the final answer is a banana. The model doesn't have room to consider alternatives.
The model didn't identify a unicorn; why does this matter? Why do we care so much about the nuances of object identification and precision? One reason is cost and time. Building a model to solve even a simple efficiency issue can take years, millions of dollars, and thousands of man hours. Over four years, John Deere spent $305 million dollars on LettuceBot, that required hand annotating and labeling approximately one million images. The goal, an object identification Roomba that would identify weeds and target them for herbicide. This model works for a single use case, iceberg lettuce thinning. Results showed between 61-82% accuracy. The model was only able to decide to detect a type of lettuce only some of the time. It was unable to assess anything else (health of the lettuce, weeds around the lettuce). It starts to matter when the details are the imperatives, and when success is based on precision, confidence, and accuracy working together.
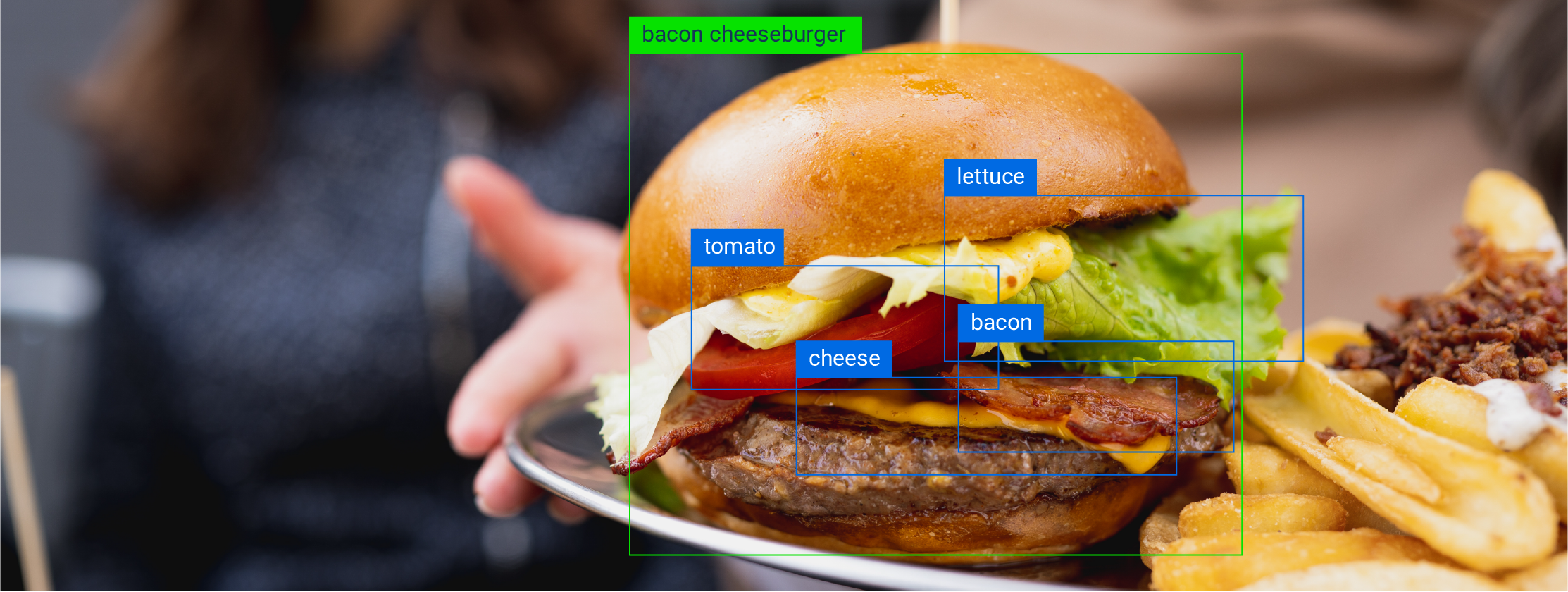
Accuracy Plus Precision: The Gold Standard
As an exercise, AI models make up a fascinating story of what could be. If we can see around corners with just human intelligence, how much farther could we forecast, anticipate, and solve with the help of millions of data points coming together to help us along? The answer is complicated.
Potential is only as good as the real world results that support it. John Deere's use case is a perfect example. While the outcome was a moderately effective object identification tool for a single plant, the potential was the elimination of all weeds for all crops with an algorithm. Well worth the years, cost, and manpower. In real world application, consumer adoption for models generated by engines is only as good as their proven accuracy and precision. The frequency that the model can choose to correctly identify an object (accuracy) and then get the answer right (precision).
For computer vision, accuracy determines the usability of the product. How many times will the model be able to decide to infer an apple on a point of sale? How often is the model deciding that it should identify the tumor in medical imaging and not something else? How often is a self-driving car deciding to recognize a human crossing the road? While confidence is the fine tuning or the boundaries of the logic to help determine the result, the final decision to infer a unicorn based on the data in the model is the percentage of accuracy. Layered on top of the decision to infer the object is then precision. The model inferred a unicorn; is it in fact a unicorn?
In conclusion. A busy supermarket loses the opportunity to decrease the wait at a checkout line because a kiosk can't identify an apple; alternatively, a patient receives an incorrect diagnosis. User adoption is driven by a product's performance in the market, and AI models are no different. 99.9% accuracy is a claim many models make, but does that claim include precision? Confidence, accuracy, and precision all work together to be able to tell us the story of an AI model. How the engine is built, what resources it uses, and how it thinks all determine if it will work in the real world.
